文章
llama.cpp使用
一、llama.cpp的下载与编译
llama.cpp可以帮助我们转化模型为gguf格式、对模型进行量化以及进行模型推理等功能。
llama.cpp Github仓库:https://github.com/ggerganov/llama.cpp
1、下载llama.cpp
我们回到root目录下,再执行下载命令
cd ~
git clone https://github.com/ggerganov/llama.cpp.git2、安装Python依赖
由于在llama.cpp项目中需要使用python脚本进行模型转换,我们需要提前配置好。这里我们再创建一个新的conda环境安装llama需要的依赖库:
#创建虚拟环境
conda create -n llama python=3.10
#进入虚拟环境
conda activate llama
#进入工程目录
cd llama.cpp
#安装环境依赖
pip install -e .3、编译安装
进入llama.cpp项目目录下,对于不同的平台需要执行不同编译指令,具体如下:
Linux:
#Linux编译指令
#直接进入工程目录make即可
make
#CUDA加速版编译
make GGML_CUDA=1Windows:
#Windows编译指令
#Windows平台需要安装cmake和gcc,如果有没有安装的请自行百度安装
mkdir build
cd build
cmake ..
cmake --build . --config Release
#CUDA加速版编译
mkdir build
cd build
cmake .. -DLLAMA_CUBLAS=ON
cmake --build . --config Release编译完后我是使用ls命令主要检查一下有没有存在llama-cli与llama-quantize两个可执行文件,我们后面会使用到,如果没有可能是在编译的时候出现了问题,可以使用“make clean”指令清除编译结果然后“make”重新编译。

二、llama.cpp的使用
!!注意:由于网上许多教程版本过低,许多原来的命令现在已经无法使用。通过查阅官方GitHub仓库说明,2024年6月官方对许多指令进行了重命名,多数在原命令前加上了“llama-”前缀,我们常用的就是llama-quantize与llama-cli。部分变动如下:
1、gguf格式转换
转换safetensors格式到gguf格式,我们主要使用的是llama.cpp提供的python脚本convert-hf-to-gguf.py。使用方式如下:
注意:指令均需要在llama.cpp项目文件夹下执行
python convert_hf_to_gguf.py --outfile <要导出的文件地址.gguf> <微调后的模型来源目录>这里我选择在autodl-tmp目录下新建一个ggufs文件夹(绝对路径:/root/autodl-tmp/ggufs)保存转换以及量化后的gguf模型文件。
我的转换指令参考如下:
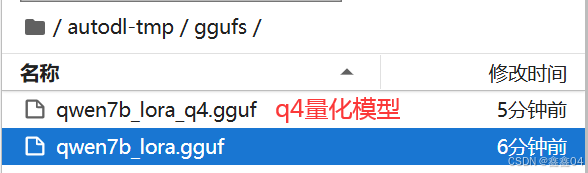
python convert_hf_to_gguf.py --outfile /root/autodl-tmp/ggufs/qwen7b_lora.gguf /root/autodl-tmp/exports转换好后,我们就可以在刚才填入得文件夹中找到gguf格式得模型文件:

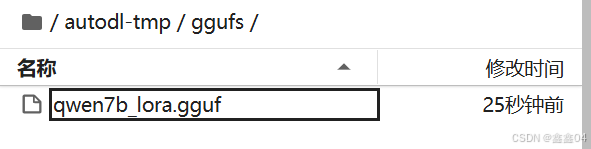
我们可以看到最终合并完后得模型文件还有15个G左右。
2、模型量化
将模型转化为gguf格式格式后,我们可以看到7b的模型大约还是有15~16GB左右,对于我们本地的电脑还是一笔不小的开销。那么我们就可以使用编译后得llama-quantize可执行文件来对模型进行进一步量化处理。量化可以帮助我们减少模型的大小,但是代价是损失了模型精度,也就是模型回答的能力可能有所下降。权衡以后我们可以选择合适的量化参数,保证模型的最大效益。
量化位数:
量化位数使用q表示,它代表存储权重(精度)的位数。q2、q3、q4… 表示模型的量化位数。例如,q2表示2位量化,q3表示3位量化,以此类推。量化位数越高,模型的精度损失就越小,模型的磁盘占用和计算需求也会越大。
我们使用llama-quantize量化模型,它提供各种量化位数的模型:Q2、Q3、Q4、Q5、Q6、Q8、F16。量化模型的命名方法遵循: Q + 量化比特位 + 变种。具体的量化参数可以在llama.cpp目录下使用./llama-quantize查看。部分示例如下: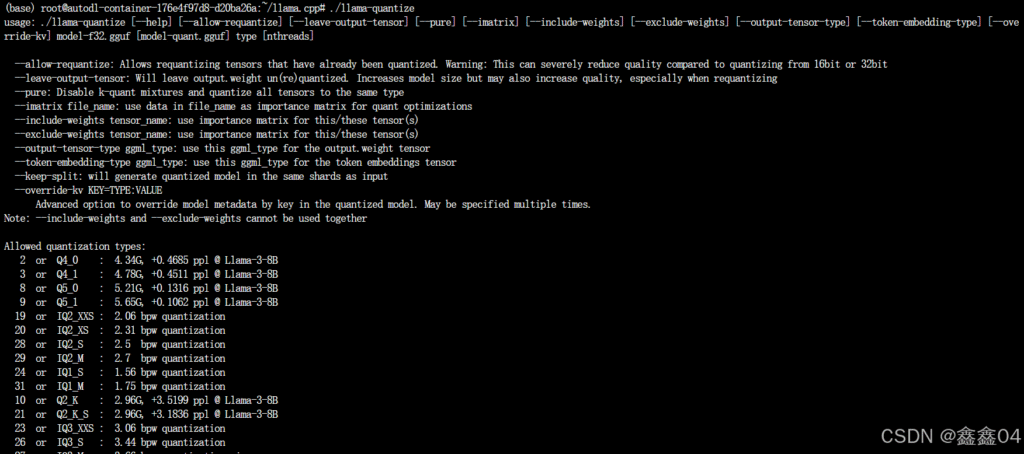
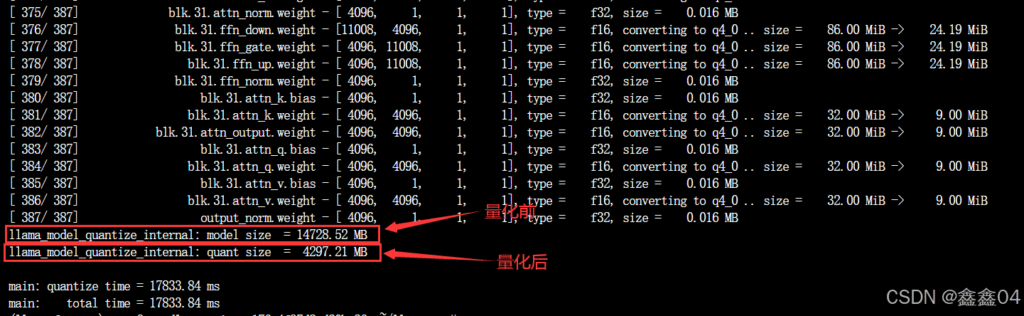
对于7b的模型,下面我对其做一个q4量化,参考指令如下:
./llama-quantize /root/autodl-tmp/ggufs/qwen7b_lora.gguf /root/autodl-tmp/ggufs/qwen7b_lora_q4.gguf q4_0量化完后,我们可以明显看到模型文件的大小小了许多,从原来的大约15GB缩小到了4GB左右,缩小了3倍。因此我们的量化作用还是很显著的。