文章
元数据管理方案
一、概念
1、元数据(Metadata)
定义:“描述数据的数据”,例如:数据库表的字段名称、数据类型、业务含义,数据表的生成规则、负责人、更新频率。
2、元模型(Meta-Model)
定义:描述元数据属性及关系的模型,即“元数据的结构定义”。
二、元数据分类
1、技术元数据
定义:描述数据的技术属性,用于系统开发、维护和数据治理,通常面向开发人员。
示例:
数据库表结构:字段名、数据类型、约束条件(非空)
2、业务元数据
定义:解释数据的业务含义,帮助业务人员理解和使用数据,确保数据符合业务逻辑。
示例:
- 业务含义、规则:目标客户、手机号码校验规则
- 指标定义:有效通话时长、签约率
业务含义来自业务术语,业务术语来自业务过程
3、管理元数据
定义:描述数据的管理属性,支撑数据安全、生命周期管理,确保数据符合管控要求。
示例:
- 基础管理属性:数据所有者、责任人、部门、安全等级、合规要求等。
- 生命周期:创建时间、更新时间、归档状态、失效日期。
当前只需要添加创建人和创建时间即可,后期可根据需要增加。
三、技术元数据管理的核心流程
1、识别技术元数据范围
明确技术元数据的覆盖范围,通常包括:
数据库层:表名、字段名、数据类型、约束、索引、分区等。
调度任务层:作业名称、调度依赖、转换规则、血缘关系等。
应用层:API接口
工具层:BI报表字段
2、采集与存储
自动化采集:通过工具扫描技术资产(如数据库Schema、SQL脚本、API文档),避免手动录入。
存储模型设计:技术元数据表、字段明细表、血缘关系表。
技术元数据分散在多系统中,采用元数据采集工具需支持多源适配。另外技术字段与业务术语映射不全,需建立映射的监控告警,定期人工补全。
3、关联业务元数据
关键动作:将技术元数据与业务术语绑定(如字段关联业务术语ID)
示例:数据库字段order.amount -> 业务术语“订单金额”
价值:实现“业务-技术”双向追溯,快速定位数据问题。
4、血缘分析与影响评估
血缘建模:构建技术数据间的上下游依赖关系(如源表->ETL->报表)
场景:评估字段变更的影响下游表的范围。
5、维护与治理
变更管理:技术元数据变更(如新增字段)需触发审批流程,更新元数据仓库。
数据质量关联:将技术元数据与质量规则绑定(如字段order.amount必须满足“非负”规则)。
四、业务元数据管理的核心流程
1、梳理业务过程
目标:识别企业核心业务活动(如销售、洽谈、签单等)。
方法:通过业务流程建模、价值链分析或与业务部门访谈实现。
输出:业务过程清单
2、定义业务术语
标准化:对业务过程中涉及的术语进行统一定义,消除歧义。
关联关系:明确术语与业务过程的归属关系(如“订单”术语“销售”业务过程)。
一方面正向创建业务术语另一方面可以根据已有表字段反推业务术语进行补充操作。
3、定义业务规则
避免歧义:仅定义术语名称(如“客户”)不够,需通过规则明确边界(如“客户=近三年有交易的企业”)。
指导技术实现:业务规则直接约束数据模型和逻辑(如“订单金额必须大于等于0”)。
支撑数据标准:规则是数据质量、一致性校验的基础(如“手机号格式校验规则”)
示例:
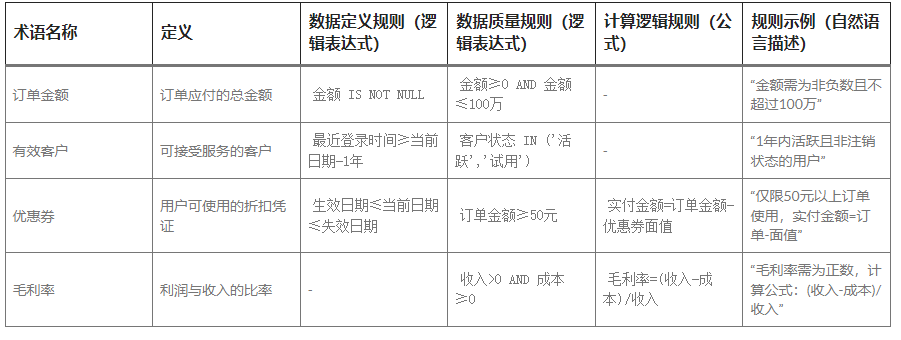
分层规则表达:
- 数据定义规则:明确术语的业务边界(如“什么是有效客户”)。
- 数据质量规则:约束数据的有效性(如“金额不能为负数”)。
- 计算逻辑规则:仅适用于派生指标(如毛利率、实付金额)。
字段填充原则:
- 若某规则类型不适用则留空(如“订单金额”无计算规则)。
- 自然语言描述需与逻辑表达式严格对应,避免歧义。
示例解析(优惠券)
术语名称:优惠券
- 定义:用户可使用的折扣凭证
数据定义规则:
- 逻辑:生效日期≤当前日期≤失效日期
- 作用:确保优惠券在有效期内才可被使用。
数据质量规则:
- 逻辑:订单金额≥50元
- 作用:防止小额订单滥用优惠券。
计算逻辑规则:
- 公式:实付金额=订单金额-优惠券面值
作用:明确如何根据优惠券计算最终支付金额。
4、持久化存储
业务过程表:过程名称、描述、所属业务域
业务术语表:术语名称、定义、业务过程外键、业务规则
5、关联技术元数据
在技术元数据(如表、字段)中通过外键引用业务术语ID,而非手动填写名称,避免人为错误,实现业务-技术血缘的自动化管理。
业务术语允许一个术语对应多个字段
6、注意事项
术语与规则同步梳理,不仅收集术语定义,还需追问:“如何判断XX是否有效?XX的计算逻辑是什么?”
规则标准化表达:自然语言描述(供业务人员理解) + 结构化逻辑(供技术实现,如SQL、正则表达式)
五、管理元数据
管理属性定义与标准化
六、血缘关系
根据表的DML逻辑可以分析出目标表与来源表进而得到以下:
1、表级血缘关系
定义:数据表之间的生成、依赖和流转关系,通过追踪数据从源表到目标表的移动路径,形成有向无环图(DAG)
作用:
- 数据溯源,定位数据来源,比如:目标表的数据从哪些源表生成或者数据异常时,逆向追踪问题源头表。
- 影响分析,评估变更影响范围,比如:修改表会影响下游哪些表或者下线旧系统时确认该系统的所有下游任务。
- 数据治理,识别关键数据资产(被大量依赖的核心表),检测循环依赖等不良设计。
- 运维效率提升,缩短故障诊断时间。
2、字段级血缘关系
定义:数据字段级别的数据流动路径,记录目标字段如何从源字段经过计算、转换或直接映射而来。
作用:
- 精细化数据溯源,精确追踪字段值的来源,定位数据问题到具体字段。
- 转换逻辑透明化,记录字段的计算规则,消除“黑盒转换”
- 影响分析精准化,评估字段变更对下游的影响范围。
数据质量监控,建立字段级数据指标检查链路,比如源头字段设置质量规则(如非空校验)自动传播到下游衍生字段。
七、元模型设计
1、主元模型存储模型
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 元数据记录ID | metadata_id | STRING | |
| 关联字段外键 | field_id | STRING | |
| 关联业务术语外键 | term_id | STRING | 可为空,部分技术字段无业务术语 |
| 敏感等级 | data_level | STRING | |
| 负责人 | manager | STRING | |
| 部门 | department | STRING |
2、库、表、字段模型
(1)数据库存储模型
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 数据库ID | database_id | STRING | |
| 数据库名称 | database_name | STRING | |
| 数据库类型 | db_type | STRING | Mysql/doris/tidb |
(2)表存储模型
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 表ID | table_id | STRING | |
| 数据库ID | database_id | STRING | |
| 表名称 | table_name | STRING | |
| 表类型 | table_type | STRING | UNIQUE/Duplicated/Aggragated |
| 副本数 | bucket_num | BIGINT | |
| 表注释 | table_comment | STRING |
(3)字段存储模型
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 字段ID | field_id | STRING | |
| 表ID | table_id | STRING | |
| 字段名称 | field_name | STRING | |
| 字段类型 | data_type | STRING | STRING/BIGINT/DECIMAL/DATETIME |
| 是否主键 | is_pk | STRING | 0, 1 |
| 是否分区字段 | is_partition | STRING | 0, 1 |
| 字段注释 | table_comment | STRING | |
| 是否继承源属性 | is_inherited | STRING | 0, 1 |
| 来源字段 | source_field_id | STRING |
3、业务过程、业务术语模型
(1)业务过程
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 业务过程ID | process_id | STRING | |
| 业务过程名称 | process_name | STRING | |
| 主题域 | Domain | STRING |
(2)业务术语
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 业务术语ID | term_id | STRING | |
| 业务过程ID | process_id | STRING | |
| 业务名称 | term_name | STRING | |
| 术语定义 | definition | STRING | |
| 数据定义规则 | d_rule | STRING | |
| 数据质量规则 | q_rule | STRING | |
| 计算逻辑规则 | c_rule | STRING | |
| 规则示例 | example | STRING |
上表中未列出业务含义,但是根据表结构可知:
- 业务含义=业务术语+规则定义
通过这种组合方式,可以在不改变表结构的前提下,完整表达字段的业务语义。
场景1:
同一术语在不同部门定义可能不一致(即“一词多义”或“多词一义”),通过将术语表与业务过程表动态关联,并利用联合组件(术语ID+业务过程ID)实现上下文相关的术语定义管理,既能解决多部门定义冲突,又能保持数据的业务可追溯性。
示例:
| 术语ID | 术语名称 | 业务过程ID | 过程名称 | 上下文定义 | 关联外键 |
| CUST | 客户 | SALES_ORDER | 销售订单 | 签订合同且支付定金的法人 | Sales_cust_id |
| CUST | 客户 | FINANCIAL_BILL | 财务结算 | 近三年有实际付款记录的实体 | Bill_payer_id |
| CUST | 客户 | AFTER_SALES | 售后服务 | 已购买产品并注册保修记录的终端用户 | Service_cust_id |
场景2:
字段表示一个枚举字典值,可以在业务术语定义说明具体枚举值定义,以及对应具体的业务规则。
| 中文名称 | 英文名称 | 数据值 | 说明 |
| 业务术语ID | term_id | COUPON_TYPE | 优惠券的唯一标识 |
| 业务过程ID | process_id | ORDER_PAYMENT | 关联到订单支付业务过程 |
| 术语名称 | term_name | 优惠券类型 | |
| 术语定义 | definition | 1:满减券 2:折扣券 3:运费券 | 存储枚举值基础定义 |
| 数据定义规则 | d_rule | 值域范围(1, 2, 3) | 限定字段取值范围 |
| 数据质量规则 | q_rule | 满减券:订单金额≥门槛金额。折扣券:不可叠加使用 | 拆分枚举校验规则 |
| 计算逻辑 | c_rule | 1:实付=订单金额-202:实付=订单金额*0.83:运费=0 | 枚举值对应的计算逻辑 |
| 规则示例 | example | 满减券:100元订单实付80元。折扣券:100元订单实付80元 | 示例需体现不同枚举值的差异 |
4、血缘关系
(1)表级血缘关系
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 表血缘ID | table_rel_id | STRING | |
| 目标表ID | target_table_id | STRING | |
| 来源表ID | source_table_id | STRING |
(2)字段级血缘关系
| 中文名称 | 英文名称 | 数据类型 | 备注 |
| 字段血缘ID | field_rel_id | STRING | |
| 目标表ID | target_table_id | STRING | |
| 目标表字段ID | target_field_id | STRING | |
| 来源表ID | source_table_id | STRING | |
| 来源表字段ID | source_field_id | STRING |
5、元数据继承
场景:创建ods层ods_tb01表A字段元数据,补充了该字段的技术元数据、业务元数据以及管理元数据。DWD层dwd_tb01表A字段来自ods_tb01.A,正常的做法需要再次录入A字段的元数据信息,后续ADS层ads_tb01表A字段来自dwd_tb01.A,那么还需要录入一次,造成同一含义、来源的字段元数据冗余,另外如果后续对其中一层元数据信息进行变更将会导致每层同一含义、来源字段元数据不一致。
在字段模型中添加is_inherited就是为了标识是否继承来源表的字段。如果是则记录来源表字段的field_id到source_field_id中。同时主元模型中添加的元数据记录field_id来自自身表,term_id则来自继承字段对应的term_id
也就是字段模型标记继承关系,主元模型继承业务语义。
另元数据是自动采集的,也就是表是先建好的,然后获取的字段技术属性已经存储到对应的字段表中。如果is_inherited标记使用了继承来源字段,可以判断当前字段和源头字段的技术属性是否有差异,类似告警督促修改保持统一性。元数据也需要定时任务检测是否发生了变更及时更新技术元数据。