文章
数据质量监控
数据质量实时监控方案
1. 整体架构
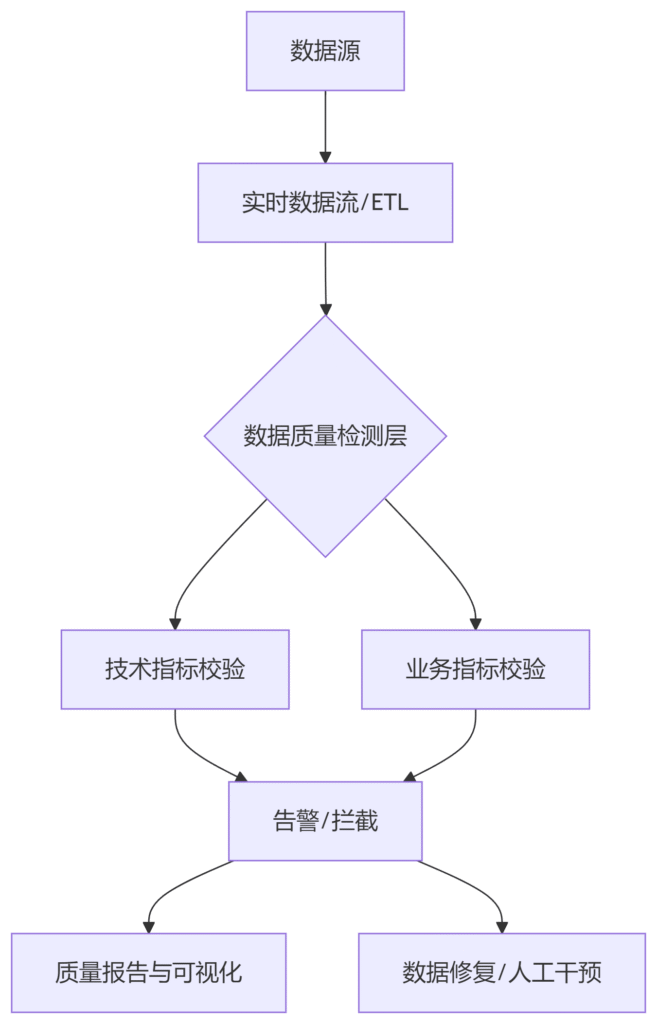
2. 技术指标与校验规则
| 技术指标 | 校验规则 | 校验方法 | 实时实现示例 |
|---|---|---|---|
| 完整性 | 关键字段非空率≥99% | 统计字段空值占比,触发阈值告警 | Flink SQL:COUNT(CASE WHEN field IS NULL THEN 1 END) / COUNT(*) |
| 准确性 | 数值字段在合理范围(如年龄≤150) | 范围校验、正则表达式匹配 | 规则引擎(如Apache Griffin):WHERE age > 150 THEN 'ERROR' |
| 一致性 | 跨系统同一主键数据差异率<0.1% | 实时对比源系统和目标系统的关键字段(如订单金额) | Flink双流Join:source_stream JOIN target_stream ON key WHERE amount_diff > 0 |
| 唯一性 | 主键重复数=0 | 实时去重计数(如基于主键的分布式计数器) | Redis HyperLogLog或Flink DISTINCT(key).COUNT() |
| 及时性 | 数据从产生到入库延迟<10秒 | 打时间戳并计算端到端延迟 | 在数据中注入event_time,Flink计算PROCESS_TIME - event_time |
| 有效性 | 枚举值符合预定义(如性别∈['男','女']) | 实时校验字典表 | 流式Join维度表:JOIN dim_gender ON raw_data.gender = dim_gender.code |
技术实现工具:
- 流处理框架:Apache Flink、Spark Streaming
- 质量规则引擎:Great Expectations、Apache Griffin
- 实时存储:Redis(计数器)、Kafka(告警事件)
3. 业务指标与校验规则
| 业务指标 | 校验规则 | 校验方法 | 实时实现示例 |
|---|---|---|---|
| 业务规则合规性 | 贷款申请金额≤客户信用额度×2 | 实时调用风控模型或信用额度服务 | Flink异步IO:调用风控API校验IF loan_amount > credit_limit*2 THEN REJECT |
| KPI可信度 | 实时GMV波动率<±5%(同比昨日同时段) | 滑动窗口统计GMV并与历史数据对比 | Flink Window Aggregation:SUM(amount) OVER 1h + 同比计算 |
| 数据关联性 | 订单状态为“已支付”时,支付流水必存在 | 实时关联订单流和支付流,检查支付流水缺失的订单 | Flink Interval Join:orders LEFT JOIN payments WITHIN 5m ON order_id |
| 业务时效性 | 风控审批响应时间<1秒 | 监控从请求到结果的端到端时间 | 在审批日志中打时间戳,计算end_time - start_time |
| 风险性指标 | 同一IP高频注册(>5次/分钟) | 滑动窗口统计IP注册频次 | Flink Keyed State + COUNT_STATE(ip) + 阈值告警 |
业务规则实现工具:
- 复杂规则:Drools规则引擎、Flink CEP(复杂事件处理)
- 外部服务调用:异步IO(如风控API)
- 实时数仓:Kafka + Flink + HBase(关联查询)
4. 告警与修复机制
告警分级
- P0(阻塞):数据中断、核心KPI失效(如GMV计算异常) → 短信/电话告警
- P1(严重):业务规则违规(如超额贷款) → 企业微信/钉钉告警
- P2(警告):技术指标异常(如字段空值率超阈值) → 邮件告警
修复流程
- 自动修复:
- 丢弃无效数据(如重复记录)
- 补发延迟数据(通过死信队列重试)
- 人工干预:
- 数据溯源修复(如从备份系统补录)
- 业务规则调整(如临时放宽风控阈值)
5. 可视化与报告
- 实时看板:Grafana展示核心指标(如数据延迟、错误率)
- 质量报告:每日/每周汇总数据质量评分(按技术+业务维度)
- 根因分析:关联错误日志与数据血缘(如Apache Atlas)
方案优势
- 实时性:从T+1提升到秒级监控,快速拦截问题数据。
- 灵活性:支持动态加载规则(如通过配置中心更新业务阈值)。
- 可扩展:模块化设计,可新增技术/业务指标。
适用场景:电商实时订单、金融风控、IoT设备数据等对时效性要求高的领域。
如果需要更具体的某环节实现代码(如Flink规则逻辑),可进一步细化!
离线数仓数据质量监控方案
1. 整体架构

2. 技术指标与校验规则
| 技术指标 | 校验规则 | 校验方法 | 实现示例 |
|---|---|---|---|
| 完整性 | 关键字段空值率<5% | 统计空值占比,分区级校验 | Hive SQL:SELECT COUNT(CASE WHEN field IS NULL THEN 1 END)/COUNT(*) FROM table WHERE dt='${date}' |
| 准确性 | 数值字段在合理范围(如年龄≤150) | 范围校验、异常值检测 | Spark代码:df.filter("age > 150").count() → 触发告警 |
| 一致性 | 跨表同一主键数据差异数=0 | 对比两张表的关联字段(如订单ID对应的金额) | Hive SQL:SELECT a.order_id FROM table_a a LEFT JOIN table_b b ON a.order_id=b.order_id WHERE a.amount != b.amount |
| 唯一性 | 主键重复数=0 | 分组计数检查 | Hive SQL:SELECT user_id, COUNT(*) FROM user_table GROUP BY user_id HAVING COUNT(*) > 1 |
| 及时性 | 每日分区数据按时生成(如9:00前) | 检查分区是否存在及数据量是否正常 | Shell脚本:hdfs dfs -ls /data/warehouse/table/dt=${date} | wc -l |
| 有效性 | 枚举值符合字典表(如省份∈省份列表) | 关联字典表校验 | Spark SQL:SELECT invalid.* FROM raw_data invalid LEFT JOIN dim_province dim ON invalid.province=dim.code WHERE dim.code IS NULL |
技术实现工具:
- SQL校验:Hive、Spark SQL
- 调度系统:Airflow(集成质量检查任务)
- 规则引擎:Griffin、Deequ(AWS开源工具)
3. 业务指标与校验规则
| 业务指标 | 校验规则 | 校验方法 | 实现示例 |
|---|---|---|---|
| 业务规则合规性 | 订单折扣率≤30%(防刷单) | 计算折扣订单占比 | Hive SQL:SELECT COUNT(CASE WHEN discount_amount/order_amount > 0.3 THEN 1 END)/COUNT(*) FROM orders WHERE dt='${date}' |
| KPI可信度 | 日活用户数波动<±10%(同比上周同日) | 对比历史同期数据 | Spark代码:val today_dau = spark.sql("SELECT COUNT(DISTINCT user_id) FROM log WHERE dt='${date}'")val last_week_dau = ...IF (abs(today_dau - last_week_dau)/last_week_dau > 0.1) THEN ALERT |
| 数据关联性 | 用户购买记录必须对应会员表中的用户 | 左关联验证用户是否存在 | Hive SQL:SELECT a.user_id FROM orders a LEFT JOIN members b ON a.user_id=b.user_id WHERE b.user_id IS NULL AND a.dt='${date}' |
| 数据价值密度 | 日志表中无效请求占比<20% | 过滤无效状态码(如404)并计算比例 | Spark SQL:SELECT COUNT(CASE WHEN status_code='404' THEN 1 END)/COUNT(*) FROM log WHERE dt='${date}' |
| 风险性指标 | 同一设备号当日登录次数>50(防爬虫) | 分组统计设备登录频次 | Hive SQL:SELECT device_id, COUNT(*) FROM login_log WHERE dt='${date}' GROUP BY device_id HAVING COUNT(*) > 50 |
业务规则实现工具:
- 复杂逻辑:Spark代码(Scala/Python)
- 调度集成:Airflow的PythonOperator调用业务校验脚本
- 外部依赖:通过JDBC查询业务数据库比对
4. 告警与修复机制
告警分级
- P0(阻塞):核心表数据缺失、主键重复 → 电话/企业微信告警,阻塞下游任务
- P1(严重):业务KPI异常(如GMV下跌超阈值) → 邮件+钉钉告警
- P2(提示):字段空值率超预期 → 日志记录,次日晨会同步
修复流程
- 自动修复:
- 重跑失败分区(通过Airflow回调机制)
- 数据回滚(从备份表恢复问题分区)
- 人工干预:
- 修正源数据(协调业务系统补录)
- 调整规则阈值(如放宽折扣率至35%)
5. 监控与可视化
质量报告
- 日报:
## 数据质量日报(${date})
- 技术指标合格率:98.5% ✅
- 异常表:user_info(空值率8%,超阈值5%)
- 业务指标异常:
- 折扣订单占比35%(阈值30%),疑似刷单 ⚠️- 可视化看板:
- Superset/Grafana展示趋势(如空值率、KPI波动)
- 血缘图谱标记问题表影响范围(如Apache Atlas)
根因分析
- 通过Hive元数据+调度日志定位:
-- 检查异常数据来源
SELECT * FROM source_table WHERE dt='${date}' AND field IS NULL;方案优势
- 低成本:基于SQL和开源工具,无需实时计算资源。
- 强适配:与离线调度系统(如Airflow)深度集成,天然契合T+1场景。
- 可追溯:分区级校验结果留存,便于回溯问题。
典型执行流程:
- 每日8:00 ETL任务完成 → 触发质量检查作业
- 9:00生成质量报告 → 异常告警发送
- 10:00前人工确认/修复 → 下游任务继续执行
如果需要具体代码模板(如Airflow DAG配置或Spark校验脚本),可进一步补充!