文章
问题数据产生与检测流程
在离线数仓的典型流程中,数据质量监控确实是事后检查机制,问题的发现和修复遵循以下闭环流程:
1. 问题数据产生与检测流程

- 关键点:
- 问题数据已进入数仓(ODS或DWD层),质量监控是滞后检测。
- 修复需从业务系统源头修正,再重新同步到数仓(避免直接修改数仓数据导致血缘混乱)。
2. 各环节详细说明
(1) 数据同步与ETL执行
- 数据源:业务数据库(MySQL/Oracle)、日志文件等。
- 同步方式:
- 每日全量/增量同步(如Sqoop、DataX抽取到ODS层)。
- 此时问题数据已进入数仓(如字段空值、格式错误)。
(2) 数据质量监控触发
- 执行时机:ETL任务完成后触发(如Airflow任务流中追加质量检查节点)。
- 检测范围:
- ODS层:校验原始数据是否符合预期(如字段完整性)。
- DWD/DWS层:校验加工逻辑是否正确(如指标一致性)。
(3) 问题修复流程
- 步骤:
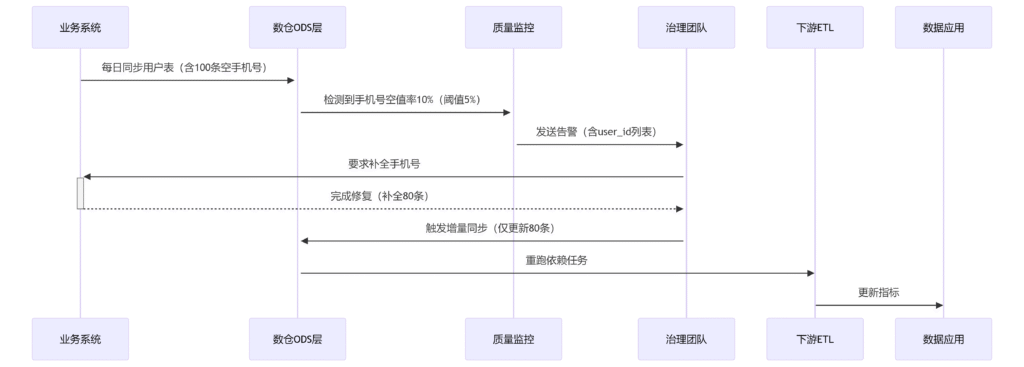
- 质量监控发现异常(如用户表手机号空值率超阈值)。
- 告警发送给数据治理团队,附带异常数据样本(如Hive分区路径、主键列表)。
- 治理团队协调业务系统:
- 修正源数据(如让运营补全用户手机号)。
- 业务系统重新生成正确数据。
- 重新同步到数仓:
- 方式一:次日全量同步覆盖旧分区。
- 方式二:针对问题数据增量补录(需标记修复批次)。
(4) 数据回溯与重跑
- 下游依赖:
- 修复后的数据需触发下游ETL重跑(如从ODS层重新加工到DWS层)。
- 工具支持:
- Airflow手动触发DAG重跑。
- 数据版本控制(如Hive分区
dt=20240501_repair)。
3. 关键设计建议
(1) 避免直接修改数仓数据
- 原则:数仓数据应严格通过ETL从源头同步生成,禁止手动修改(除非紧急故障修复)。
- 例外情况:
- 源系统无法修复(如历史日志丢失)→ 在数仓专用纠错表(
table_error_fixed)中补录,并通过视图关联到主表。
- 源系统无法修复(如历史日志丢失)→ 在数仓专用纠错表(
(2) 问题数据隔离
- 方法:
- 自动将问题数据写入
表_error分区(如dt=20240501_error)。 - 下游任务优先读取正常分区,避免污染分析结果。
- 自动将问题数据写入
(3) 修复效率优化
- 增量修复:
- 仅同步修复的记录(需业务系统提供数据变更日志)。
- 工具示例:
- MySQL Binlog + Canal → 同步到ODS层。
- 使用
MERGE INTO语法更新数仓数据(Hive 3.0+支持)。
4. 完整流程示例(以用户表手机号缺失为例)
5. 工具链推荐
| 环节 | 工具 |
|---|---|
| 数据同步 | Sqoop、DataX、Flink CDC |
| 质量监控 | Griffin、Deequ、Great Expectations |
| 调度与重跑 | Airflow(PythonOperator)、DolphinScheduler |
| 问题追踪 | Jira(集成告警)、Excel记录修复清单 |
| 数据血缘 | Apache Atlas、DataHub |
总结
- 核心逻辑:问题在数仓中发现,但修复必须回归业务系统,再通过标准同步机制更新数仓。
- 优势:保证数据血缘清晰,避免“脏修”导致数据不一致。
- 挑战:依赖业务系统配合,需建立跨团队协作流程(如SLA约定修复时效)。
如果需要具体某环节的代码实现(如Airflow异常处理DAG),可进一步细化!