文章
技术元数据与血缘关系
SQL逻辑与血缘关系确实需要独立于基础技术元数据存储,但两者需通过关联键保持连接。以下是专业级的设计方案:
一、SQL逻辑与血缘的独立存储必要性
| 对比维度 | 基础技术元数据(表结构) | SQL逻辑与血缘数据 |
|---|---|---|
| 数据性质 | 静态信息(DDL定义) | 动态信息(ETL/查询行为) |
| 变更频率 | 低频(表结构变更时) | 高频(每次SQL执行可能变化) |
| 数据量级 | 千~万级记录 | 百万级+(每条SQL及其血缘) |
| 典型查询 | "有哪些表?" | "这个字段被哪些SQL加工?" |
二、推荐存储模型(工业级实践)
1. 核心表结构设计
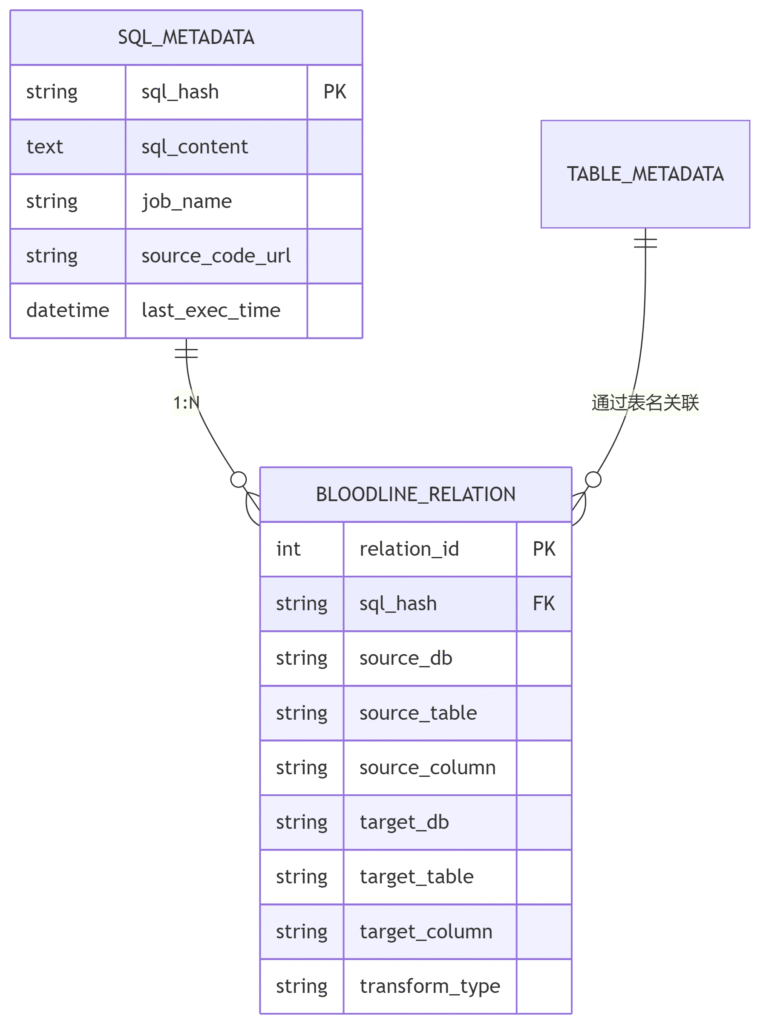
2. 建表示例(MySQL)
-- SQL逻辑存储表
CREATE TABLE meta_sql_logic (
sql_hash CHAR(64) PRIMARY KEY COMMENT 'SQL内容哈希',
sql_content LONGTEXT COMMENT '完整SQL文本',
sql_type ENUM('ETL','QUERY','DML') COMMENT 'SQL类型',
job_name VARCHAR(255) COMMENT '调度任务名',
git_repo VARCHAR(512) COMMENT '代码仓库链接',
parse_time DATETIME COMMENT '解析时间',
INDEX idx_job (job_name)
) COMMENT 'SQL逻辑存储';
-- 血缘关系表
CREATE TABLE meta_bloodline (
relation_id BIGINT AUTO_INCREMENT PRIMARY KEY,
sql_hash VARCHAR(64) COMMENT '关联的SQL哈希',
source_db VARCHAR(100) COMMENT '源库名',
source_table VARCHAR(100) COMMENT '源表名',
source_column VARCHAR(100) COMMENT '源字段',
target_db VARCHAR(100) COMMENT '目标库',
target_table VARCHAR(100) COMMENT '目标表',
target_column VARCHAR(100) COMMENT '目标字段',
transform_expr TEXT COMMENT '转换逻辑表达式',
relation_type ENUM('FIELD','TABLE') COMMENT '血缘粒度',
FOREIGN KEY (sql_hash) REFERENCES meta_sql_logic(sql_hash),
INDEX idx_src (source_db, source_table, source_column),
INDEX idx_tgt (target_db, target_table, target_column)
) COMMENT '字段级血缘关系';三、关联查询示例
1. 查看某表的所有上游依赖
SELECT
s.job_name,
b.source_db, b.source_table, b.source_column,
b.transform_expr
FROM meta_bloodline b
JOIN meta_sql_logic s ON b.sql_hash = s.sql_hash
WHERE b.target_db = 'dw' AND b.target_table = 'fact_order';2. 分析字段级完整血缘
WITH RECURSIVE bloodline_path AS (
-- 初始查询:目标字段
SELECT
sql_hash, source_db, source_table, source_column,
target_db, target_table, target_column,
transform_expr, 1 AS depth
FROM meta_bloodline
WHERE target_db = 'ads' AND target_table = 'user_profile' AND target_column = 'vip_score'
UNION ALL
-- 递归查询:向上追溯
SELECT
b.sql_hash, b.source_db, b.source_table, b.source_column,
b.target_db, b.target_table, b.target_column,
CONCAT(b.transform_expr, ' -> ', p.transform_expr),
p.depth + 1
FROM meta_bloodline b
JOIN bloodline_path p ON
b.target_db = p.source_db AND
b.target_table = p.source_table AND
b.target_column = p.source_column
)
SELECT * FROM bloodline_path ORDER BY depth;四、与基础元数据的协同
1. 关联关系图
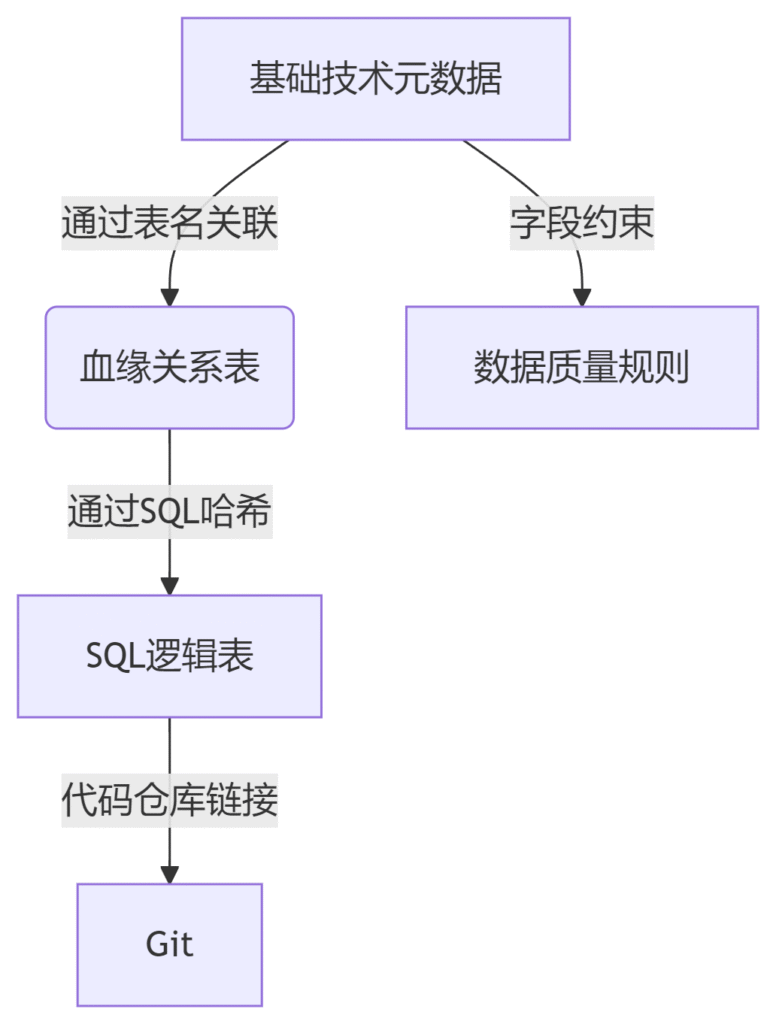
2. 数据流向
- ETL开发:开发人员在Git提交SQL脚本
- CI/CD:自动触发元数据解析器
# 示例解析流程
def parse_etl(sql_file):
# 解析SQL获取输入输出表
tables = extract_tables(sql_file)
# 生成AST分析字段映射
bloodline = analyze_ast(sql_file)
# 存储到元数据库
save_to_metadata_db(tables, bloodline)元数据服务:提供血缘可视化API
// 返回示例
{
"target_table": "fact_order",
"upstream": [
{
"source_table": "ods_order",
"transform": "order_amount*exchange_rate",
"sql_job": "daily_order_etl"
}
]
}五、性能优化策略
| 场景 | 优化方案 | 实施示例 |
|---|---|---|
| 高频血缘查询 | 使用图数据库存储关系 | Neo4j构建(:Table)-[:TRANSFORM]->(:Table)关系 |
| 大规模历史版本 | 按时间分区 | PARTITION BY RANGE (YEAR(parse_time)) |
| 实时血缘分析 | 内存缓存热门SQL | Redis缓存TOP1000条SQL的血缘关系 |
| 全文检索 | 为SQL内容建立倒排索引 | Elasticsearch索引sql_content字段 |
六、企业级实施建议
- 版本控制:
- 将SQL哈希与Git commit ID绑定
ALTER TABLE meta_sql_logic ADD COLUMN git_commit CHAR(40);血缘保鲜:
- 每日凌晨校验血缘有效性
# 校验脚本示例
for tbl in $(get_changed_tables); do
verify_bloodline $tbl || alert "血缘断裂: $tbl"
done安全隔离:
- 敏感字段(如手机号)的血缘关系加密存储
CREATE VIEW v_secure_bloodline AS
SELECT * FROM meta_bloodline
WHERE sensitivity_level < 3; -- 仅展示非密级血缘总结
- 必须分开存储:SQL逻辑/血缘 vs 基础技术元数据,因二者在生命周期、数据量和使用场景上存在本质差异
- 通过外键关联:
sql_hash和表名作为连接枢纽 - 分级存储策略:
- 热数据:关系型数据库(MySQL/PostgreSQL)
- 温数据:图数据库(Neo4j)
- 冷数据:对象存储(S3)
这种设计下,某银行客户实现了:
- 数据变更影响分析从小时级→秒级
- 故障溯源时间缩短85%
- 合规审计效率提升70%