文章
数据质量监控落地实施方案
一、使用场景
| 组件 | 角色 | 数据特点 |
| 业务库(Mysql、Tidb) | 源头 | 实时产生Binlog |
| CDC -> Kafka | 传输层 | 每条Binlog事件以JSON形式入Kafka(含before/after/op) |
| Kafka消费 -> Doris | 入仓 | 将Kafka中的变更写入Doris ODS表 |
| Binlog监控 | 在kafka消费阶段实时校验每条事件 | 仅看最新变更,无历史 |
| 离线监控 | 直接查Doris各层表(ODS/DWD/DWS/ADS) | 全量扫描,含历史数据 |
关键区分:
- Binlog监控:实时、流式、单条事件、无历史上下文 -> 发现“此刻正在发生的错误”
- 离线监控:批处理、全表、有历史 -> 发现“当前所有存在的问题”
二、明确监控目标
| 监控类型 | 目的 | 输出 |
| Binlog 监控 | 实时捕获业务库写入的异常变更,记录下来用于根因分析和治理 | 结果表记录:单条违规事件(含主键、字段、新旧值、时间) |
| Doris离线监控 | 全量扫描输出各层,发现数据加工错误,历史累计问题、逻辑矛盾。 | 结果表记录:违规记录列表(可含多条历史数据) |
Binlog监控不是为了拦截kafka消息,也不是为了保护Doris,而是为了“取证”。
三、监控分级
1、表分级
核心原则:用业务影响+数据风险双维度打分,避免主观判断。
实操步骤:每每个表确认以下4个问题(打√/×)
| 问题 | 权重 | 说明 |
| Q1.该表是否被核心报表、结算、风控、客户端直接依赖? | 高 | 如:订单、用户、支付、合同 |
| Q2.该表数据出错是否会导致资损、客诉、监管问题? | 高 | 如:金额、状态、身份 |
| Q3.该表是否频繁更新(>100次/天)或由人工/多系统写入? | 中 | 高频=高风险 |
| Q4.该表是否主数据或关键维度(如商品、地区、组织) | 中 | 影响下游多张表 |
分级规则:
| 类别 | 判定条件 | 监控策略 |
| A类(核心资产) | Q1√或Q2√ | Binlog + 离线双监控 |
| B类(重要配置/维度) | Q4√且Q1/Q2× | 仅离线监控 |
| C类(日志/临时/低风险) | 全部× | 暂不监控 |
附:表分级问卷表示例

2、字段筛选
明确每张表哪些字段需要监控,核心原则:只监控“关键+高风险”字段,避免全字段覆盖。
- 列出所有字段
- 从Doris或业务库建表语句获取
- 标记业务关键性
- 关键字段:用于报表、结算、用户展示、下游关联,如:user_id、phone、order_amount、status
- 非关键字段:备注、日志、临时标记,如:remark、debug_flag
- 标记数据风险
- 高风险
- 人工录入
- 多系统写入
- 逻辑复杂
- 低风险
- 系统自动生成,如create_time、update_time
- 只读字段
- 高风险
- 决策是否监控
| 业务关键性 | 数据风险 | 是否监控 | 监控类型 |
| 高 | 高 | 必须监控 | Binlog + 离线 |
| 高 | 低 | 建议监控 | 离线(防逻辑错误) |
| 低 | 高 | 可选监控 | 仅离线 |
| 低 | 低 | 不监控 |
例外:主键字段(如id,order_no)无论风险高低,必须监控唯一性+ 非空
附:字段监控决策表示例
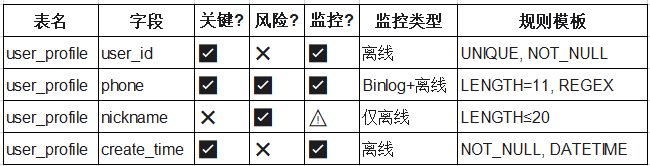
3、三级响应机制
核心原则:不是所有违规都要告警,避免“告警疲劳”
| 级别 | 触发条件 | 处理方式 | 示例 |
| L1:严重(Critical) | - 涉及资损/合规- 高频发生(>10次/天) | 实时告警 + 自动通知责任人 | 金额为负、身份证格式错误 |
| L2:警告(Warning) | - 业务逻辑错误- 低频发生 | 记录 + 每日质量日报汇总 | 状态非法 |
| L3:信息(Info) | - 非关键字段小问题- 试探性规则 | 仅记录,不告警、不日报 | 昵称超长 |
告警逻辑:
- L1:通过企业微信/邮件实时推送及写入结果表
- L2/L3:仅写入结果表,由质量日报聚合展示
说明:
- Binlog监控只配A类表的高风险字段(如phone、amount)
- 离线监控覆盖A/B类表的全关键字段(含主键、时间、状态)
- 所有规则必须指定响应级别和业务负责人
- 第一阶段只做A类表,跑同流程后再扩B类。
四、治理流程闭环
Binlog离线监控的核心价值不仅在于“发现问题”,更在于“推动问题解决”。为此,需建立标准化的治理流程,确保每条违规记录都能被追踪、处理、验证,形成闭环。
1、问题生命周期管理
每条写入结果表的违规记录,需具备明确状态,便于追踪处理进度。
| 状态 | 说明 | 责任人 | SLA(建议) |
| OPEN(待处理) | 监控发现,尚未分配 | 数据团队 | 系统自动创建 |
| ASSIGNED(已指派) | 已分配给业务/开发负责人 | 业务负责人 | 发现后1个工作日内 |
| IN_PROGRESS(修复中) | 正在修复数据或逻辑 | 开发/运营 | - |
| FIXED(已修复) | 修复完成,待验证 | 数据团队 | 分配后3日内完成修复 |
| IGNORED(已忽略) | 确认为合理场景(如测试数据) | 数据负责人 | 需填写忽略原因 |
2、治理触发机制
- L1问题:
- 自动创建治理工单,通过企业微信/邮件实时通知
- 超24小时未处理,自动升级提醒其上级
- L2问题:
- 纳入每日质量日报的待办事项模块
- 每周质量会议Review未关闭项
- 重复问题:
- 同一ruleCode在三天内触发大于5次,自动升级为L1
- 触发“根因分析”流程
3、修复验证机制
- 自动验证
- 规则持续运行,若连续7天未再触发相同规则+相同主键,系统自动标记为“已收敛”
- 在界面展示“问题趋势图”:触发次数随时间下降则证明治理有效
- 手动验证(可选)
- 支持在界面点击“重跑规则”,对指定主键或分区重新校验历史数据
- 用于验证批量修复是否生效
五、监控效果度量与持续运营
没有度量,就无法证明价值,没有运营,体系将逐渐失效,需建立数据质量健康度指标,驱动持续优化。
1、核心度量指标
| 指标 | 计算方式 | 目标 | 用途 |
| 问题发现总数 | 违规数据日新增条数 | >0 | 证明监控有效 |
| L1问题占比 | L1问题数/总问题数 | 趋势下降 | 反应治理成效 |
| 平均修复时长 | Avg(fixTime - createTime) | ≤3天 | 衡量响应速度 |
| 规则覆盖率 | 已监控字段数/A类表关键字段总数 | ≥90% | 衡量覆盖完整性 |
| 误报率 | 标记为IGNORED的L1/L2问题占比 | <5% | 衡量规则准确性 |
每日生成《数据质量健康度看板》包含上述指标趋势
2、质量日报模板
【2025-12-16 数据质量日报】
【整体情况】
- 新增问题:12 条(L1:2, L2:8, L3:2)
- 待处理 L1 问题:2 项
- 本周修复率:85%(17/20)
【L1 问题(需立即处理)】
- order_info.amount 出现负值(3 次)→ @订单组 张三
- user_profile.id_card 格式非法 → @用户中心 李四
【治理成效】
- user_profile.phone 格式错误:连续 5 天未再出现(已收敛)
- L1 问题周环比 ↓40%
【本周重点】
启动 product_sku 表 B 类监控配置3、持续优化机制
- 规则生命周期管理
- 每月Review:30天未触发的规则,评估是否下线。
- 新增业务表:自动触发表分级问卷流程
- 事件驱动优化
- 每次资损/客诉事件复盘
- 该问题是否本应被现有规则捕获
- 若否,补充新规则;如是,优化治理流程。
- 每次资损/客诉事件复盘
- 能力扩展
- 阶段1:覆盖A类表
- 阶段2:覆盖B类表+指标波动监控
- 阶段3:将部分规则迁移至源头拦截
4、规则有效性评估与生命周期管理
监控规则并非“配置即永久”,为避免规则库膨胀、维护成本上升,需建立规则生命周期管理机制。但需注意:“规则未触发”不等于“规则无价值”,应结合业务重要性与触发可能性综合判断。
(1)规则分类标准
在配置规则时,必须明确其类别,用于指导后续评估:
| 类别 | 说明 | 示例 | 是否可自动下线 |
| CORE(核心规则) | 涉及资损、合规、主数据完整性,即使长期未触发也必须保留。 | order_amount > 0、id_card格式校验、主键非空/唯一 | 否 |
| OPTIONAL(可选规则) | 用于体验优化、非关键校验或试探性监控 | 昵称长度小于20 | 是 |
(2)规则下线评估策略
| 规则类别 | 未触发时长 | 评估动作 | 审批要求 |
| OPTIONAL | ≥30天 | 列入“待清理规则清单” | 数据工程师确认即可 |
| CORE | 任意时长 | 不得自动下线 | 如需下线,须业务负责人+数据团队双签确认 |
核心判断原则:
如果这条规则明天失效,恰好发生一次违规,我们能否成否后果?
- 能承受,可清理(如昵称超长)
- 不能承受,必须保留(如金额为负)
(3)持续优化机制
- 每月自动产出《低活跃规则报告》,包含:近60天未触发的OPTIONAL规则列表,规则创建人、业务owner、最后触发时间。
- 每季度复盘:是否存在“应监控但未覆盖”的场景,是否有CORE规则长期未触发但业务逻辑已变更?(如字段废弃)
- 事件驱动更新:每次数据问题复盘,若发现“本应被捕获却未监控”,立即补充规则。
目标:保持规则库精简、精准、高信噪比,让每一条规则都值得被信任。
六、实施操作手册
1、新增一张表的监控配置流程
适用场景:业务新增核心表(如refund_order),需纳入监控
步骤1:表监控
- 填写《表分级问卷》(见3.1节)
- 输出:确认为A/B/C类
步骤2:字段筛选
- 获取表结构
- 填写《字段监控决策表》(见3.2节)
- 输出:需监控字段清单 + 监控类型
步骤3:规则配置
| 表类型 | 操作 |
| A类表 | 在monitor_rule配置binlog规则(仅高风险字段)在qulity_rule配置离线规则(所有关键字段) |
| B类表 | 仅在quality_rule配置离线规则 |
必填字段:
(1)ruleCode:按{表名}_{字段}_{序号}命名
(2)severity:L1/L2/L3
(3)owner:业务负责人
步骤4:验证规则
- binlog规则:在业务端模拟脏数据写入,检查monitor_result是否记录。
- 离线规则:手动触发调度任务,检查quality_result是否产出
2、常用规则模板库
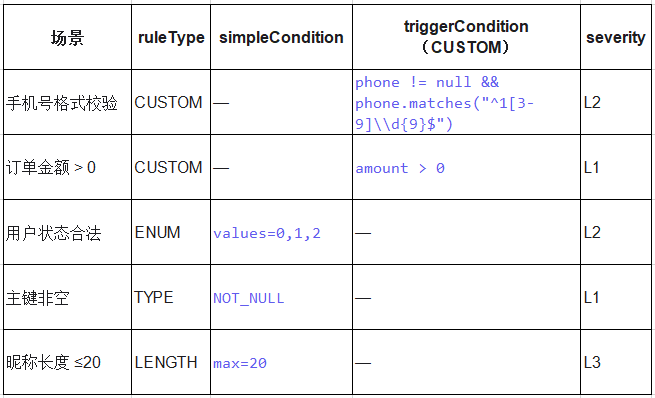
提示:
- Binlog规则中CUSTOM类型使用Sqlite SQL表达式
- 离线规则中CUSTOM类型使用Doris SQL表达式
3、问题处理SOP
当收到L1告警时,责任人应:
- 登陆监控系统,查看monitor_result中的记录
- 判断是数据问题还是逻辑问题
- 在系统中更新status = IN_PROGRESS 填写comment
- 修复后,更新status = FIXED
- 数据团队3日内校验是否收敛